Contents
I am getting zero record counts and no data is displayed, or my data is simply crazy.
Trimalyzer was designed to be a general purpose tool for common CSV data. I have a perfectly standards-obedient CSV parser, and I expect CSV files to follow certain rules, such as:
- Columns of data line up with their header field
- The number of header columns matches the number of data fields
- Commas are used for field separation only, unless they are contained within double quotes
Unfortunately, some software doesn’t follow these rules. If a file is loaded with bad CSV formatting, lines may be rejected or loaded incorrectly.
Other bugs may exist in CSV files, one example is older versions of Scan9495 which used incorrect line endings (MacOS style). The creator of Scan9495 fixed the flaw and it works fine now.
ALDLDroid also breaks with CSV file format tradition and has more columns in the header than it does in the data section. I have added temporary workarounds until these issues are fixed, but some users still find their files do not load due to other problems, and these workarounds may increase the chance of errors in other files not being caught properly.
The best thing to do is to load your data into your favorite spreadsheet program and make sure all of the columns line up. If they don’t, you can correct them there and re-export the data.
If the format seems correct, please let me know and I will try to help figure it out.
Can I load logs from two different tools simultaneously?
No.
Why doesn’t MAF mode have the same awesome functionality as VE mode?
Not enough demand or time on my part.
How do the different analysis modes work?
For the following examples, I will use a very simple log which shows:
- -20.3% trim at 950 rpm and 24 map
- +9.4% trim at 1399 rpm and 33 map
- +0% trim at 2000 rpm and 21 map
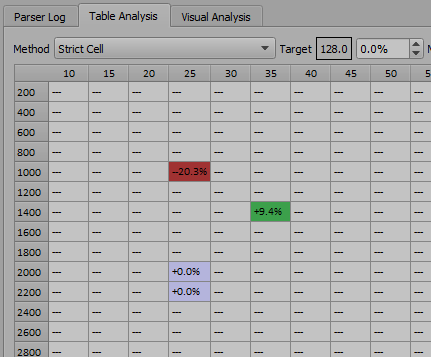
Strict Cell
Strict cell works somewhat like a spreadsheet analyzer. Data is averaged strictly into the cells where the data point exists.
It may still allow data to enter two cells if the data is exactly on a cell boundary, though, as in this example where we have an event exactly at 2000 rpm.
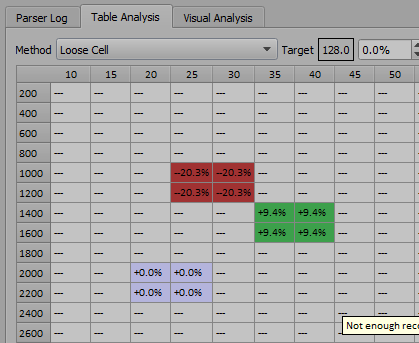
Loose Cell
This works a lot like strict cell mode, but allows data to count towards the average in more than one cell if the data is close enough to the edge (kind of like the BLM cell hysteresis in GM ECMs…)
For example, here we have data that is almost in the middle of the map and rpm axis, so it spreads to the surrounding cells.
This may seem like it would produce bad results, but in reality with larger logs, the averaging will build a much smoother and more realistic trim map than with ‘strict cell’ mode.
The amount of looseness is configurable in “Advanced Settings”
Geometric
After scaling the table so it becomes more square (as obviously RPM and MAP are at dramatically different scales), each cell establishes a dynamic relationship with each data point based both on distance and magnitude of the trim event.
It also uses low and high pass filtering, so effectively events at a great distance are rejected completely, but events at a close distance are taken at full magnitude.
For example, a massive trim event such as 20% rich will spread throughout a larger region of the table, on the assumption that such a large error definitely covers more cells, but a small 2% trim will probably localize itself within the closest cell.
This method will appear to interpolate areas of the table with no direct data based on likely patterns and assumptions, and is very useful for real-world tuning where some areas of the table are likely unreachable.
With large data sets it is extremely effective, but it does depend on a ‘sane’ base VE table to make good choices (something with some decently smooth curvature)

What do the target/max/min settings do, and when would I use them?
The target basically skews the trim corrections against a richer or leaner target. Some people would like their trims to start slightly rich then allow the ECM to lean itself out (this isn’t a bad idea) so setting the target to -3% or so would eventually result in a VE table that is 3% rich.
Max Adj. is good for tuning more unstable ECMs, or for people that just like to take their time. Setting a max adj. value of 10% will only allow changes up to 10% at a time.
Min Adj. is the minimum value that is considered worthy of change. For example, a 0.5% trim adjustment is pointless to make, and it’s likely the next run would just push it back up 0.5% again. I recommend a minimum adjustment of 1%, but perhaps higher values would be a good idea during initial VE table building.
What if my special field name isn’t detected? What if a true/false condition doesn’t work due to a strange label in my data like “yep” instead of “enabled”?
Trimalyzer uses a compiled-in, hard coded dictionary file for both auto-detection and true/false identifiers.
You can view that dictionary file here: https://github.com/resfilter/trimalyzer/blob/master/dictionary.txt
If you place a dictionary file in the same directory that Trimalyzer.exe is run from, it will override the built in dictionary completely.
A few points for your custom dictionary updates:
- Edit at your own risk
- Never change the first word of a dictionary line
- The values are not case sensitive
- The dictionary has weak error checking, so placing odd values in it may cause Trimalyzer to crash
- If you need a comma within a field, you can quote the string like “comma,ok” and it should work.
- If you find a common ADX field that isn’t in my dictionary, you’re somewhat obligated to provide the changes so I can incorporate it, and other users can benefit.
Does it analyze wideband data?
Yeah, kinda!
- Set ‘Trim Bank A’ to your wideband data column (and also bank B if you have dual widebands)
- Disable the ‘INT Bank A’ and ‘INT Bank B’ fields by setting them to -None- This is unnecessary if you’re using BETA 0.9 or newer, as it will always ignore the integrator values in arbitrary input mode!
- Set ‘Trim Input Type’ to ‘Arbitrary’
- Alter your filters (in fact for open loop tuning, the only filter you might want is ‘Coolant Temp > 60c’ or something like that
- Analyze!
You can analyze pure WOT data like that too, just filter for ‘power enrichment is true’, and build a special table with only a couple MAP columns.
The ‘Arbitrary’ trim type restricts the analyzer’s operation a little bit, since some features don’t make sense if we aren’t calculating a trim.
How do filters work?
Any record that matches a filter is considered viable trim data.
These are designed so all of your data can be dumped into trimalyzer and you filter out the bad data, avoiding the time required to find closed loop, non power enrichment, reasonable coolant temp data we want for tuning.
Example filters that are a good idea:
- Coolant temp is reasonable (above thermostat temperature?)
- Closed loop is enabled
- Acceleration enrichment not enabled
- Throttle position above 1%
- Vehicle speed above 2 MPH
Every vehicle is different, and you must review your logs to see what kind of parameters your ECM generates when the trim data is stable and realistic.
For “True” or “False”, your data must be named as one of the following:
TRUE,1,closed,close,set,active,true,enabled,enable,on,ok,true,good,power,ae,accel,enrich,cl,learn,trim FALSE,0,open,unset,inactive,false,disabled,disable,off,err,error,false,failed
After analyzing, see the “Parser Log” tab, where a filter list will show you which filters are affecting your data.
When you find good filters, simply press ‘Remember’ and they can be recalled next time.
Filters do not affect knock mapping.